- Products

AI Text Moderation
Accurately identify sensitive, violent, abusive, advertising and other illegal content

Image Moderation
Monitoring various of violations, carrying massive a image detection requests

Audio Moderation
High precision multi scene multi language violation audio recognition

Video Moderation
360 degree all-round detection, comprehensive identification of illegal video content

Audio and Video Streaming Moderation
Accurately and efficiently identify risky content in video and audio streams

Visual Tag Recognition
Recognize image content and return business tags

Audio Tag Recognition
Accurately identify audio information beyond content

Device Fingerprint
Accurately recognize fake devices, such as virtual devices and phone emulators

Fraud Prevention for Registration and Login
Real-time defense against spam registration and malicious login activities

Manual Audit Service
Humanized manual audit platform friendly to both auditors and audit management

Intelligent Audit Platform
Global, professional, efficient and highly accurate human audit service covering 8 languages

Intelligent CAPTCHA
Our diverse forms and multifunctional CAPTCHAs offer superior risk verification capabilities
- Solutions

Live Streaming
Comprehensive content moderation solution

Social Media
Technical base capacity of social dating business growth and operation

Community Forum
Analyze user's behavior and refine community operations based on content

Gaming
Solution for content risk management in the online gaming

Generative AI Moderation
Full-path content risk control solution

Minor Protection Solution
Purify negative information in minors' online space
- Customers
- Blog
- API Documentation
- About Us
- DemoNEW
Why NEXTDATA ?
Rich Multidimensional Capabilities
For noisy audio content in various scenarios, our system not only reduces noise and extracts content but also maximizes the recognition of timbre, environmental scenes, and other audio information, striving to restore the original audio as much as possible.

Flexible Configuration
Leveraging numerous years of risk control expertise and the robust product capabilities of Tianjing, we offer a combined recognition of "content + information" for audio, achieving a dual-enhancement in recognition capabilities.
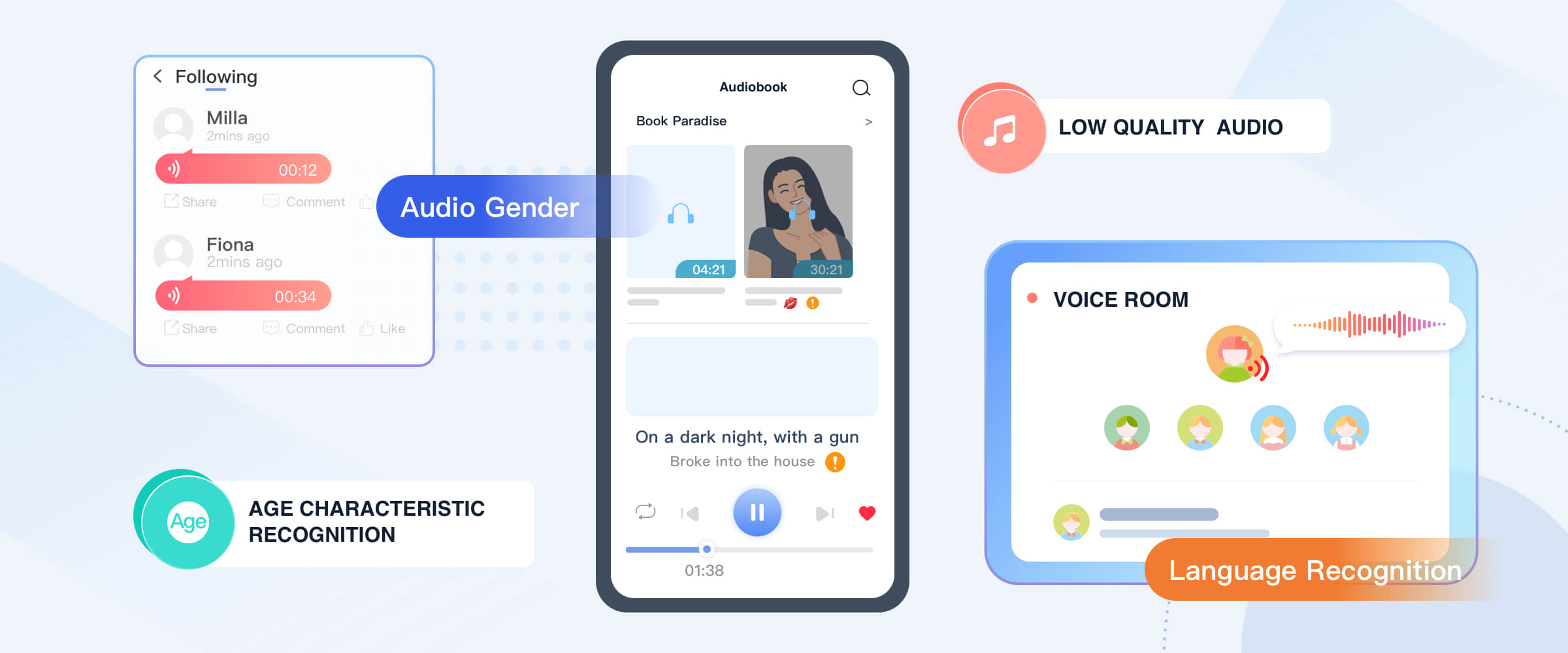
Various Type of Audio Detection

Timbre Recognition
Accurately identifies different voice tones such as young boys, mature men, and young girls.

Gender Recognition
Accurately detects whether the audio corresponds to male or female characteristics.

Language Recognition
Precisely recognizes various languages, including Mandarin, English, Tibetan, Uyghur, Korean, and other ethnic languages.

Age Recognition
Accurately identifies different age groups in audio, such as children, youth, middle-aged, and elderly.

Scenario Recognition
Precisely identifies different audio contexts, such as movies, singing, and other scenarios.

Synthetic Voice Detection
Accurately detects whether the audio is deep synthetic, such as TTS (text-to-speech) synthesis or voice changers.
Scenario Customization
With flexible and robust machine learning capabilities, we provide tailored audio recognition functions and services for various industries.
Support Audio Tag Recognition in Multiple Scenarios
Quick Access Guide

One-click Application
Click free trial to create a test service
Solution Formulation
Our solutions experts will contact you promptly
API Interface
Test quickly connects to the product for product testing
- info@nextdata.ai
- 6 RAFFLES QUAY #14-06 SINGAPORE (048580)
 WhatsApp: +86 18302808016
WhatsApp: +86 18302808016